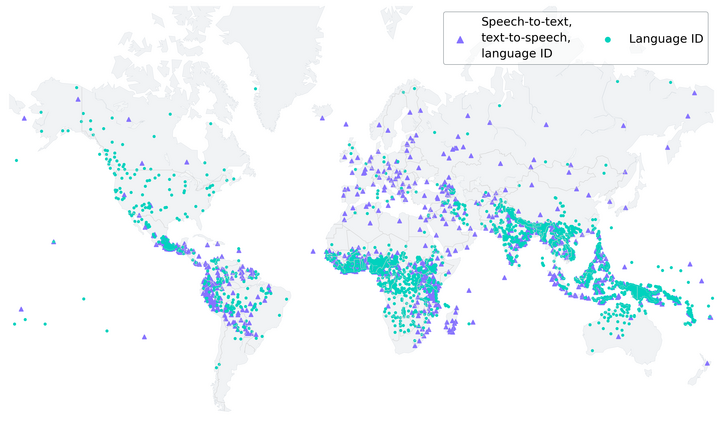
Meta has developed an AI language model capable of recognising over 4,000 spoken languages and performing text-to-speech and speech-to-text conversions for more than 1,100 languages. Through its Massively Multilingual Speech (MMS) project, Meta aims to preserve language diversity and encourage further research in this field.
The company said creating high-quality machine learning models for these tasks typically requires substantial amounts of labelled data, such as audio recordings and transcriptions. However, such data is often scarce, especially for the majority of languages. Existing speech recognition models cover only around 100 languages, which is a small fraction of the 7,000+ languages spoken worldwide. Furthermore, nearly half of these languages are at risk of extinction within our lifetime.
Meta took an unconventional approach to collect audio data by leveraging translated religious texts, like the Bible, which have been translated into numerous languages and extensively studied for text-based language translation research. These translated texts provide publicly available audio recordings of people reading them in different languages. By incorporating these unlabelled recordings into their model training, Meta expanded the number of supported languages to over 4,000.
Meta clarifies that although the audio recordings are of religious content, the model’s training is not biased towards producing more religious language. This is attributed to the use of a connectionist temporal classification (CTC) approach, which is more constrained compared to large language models (LLMs) or sequence-to-sequence models for speech recognition.
After enhancing the usability of the data through an alignment model, Meta employed its self-supervised speech representation learning model, wav2vec 2.0, to train on the unlabelled data. The combination of unconventional data sources and self-supervised learning yielded impressive results, with the MMS models outperforming existing models and covering ten times as many languages.
Meta acknowledges that the new models are not flawless, as there is a risk of transcribing certain words or phrases wrongly, potentially leading to offensive or inaccurate language in the output. The company emphasises the importance of collaboration across the AI community for the responsible development of AI technologies.
By making the MMS models available for open-source research, Meta hopes to counteract the trend of technology marginalizing languages and supporting only a limited number of commonly spoken languages dictated by major tech companies. It envisions a future where assistive technologies, text-to-speech systems, and even virtual reality/augmented reality (VR/AR) technologies enable people to communicate and learn in their native languages.